Directly Fine-Tuning Diffusion Models On Differentiable Rewards Poster - To address this, we consider the scenario where. To solve this, we propose a novel algorithm that enables direct reward backpropagation through entire trajectories, by making the non. For instance, in the inverse folding task, we may prefer protein sequences with high stability.
To solve this, we propose a novel algorithm that enables direct reward backpropagation through entire trajectories, by making the non. For instance, in the inverse folding task, we may prefer protein sequences with high stability. To address this, we consider the scenario where.
For instance, in the inverse folding task, we may prefer protein sequences with high stability. To address this, we consider the scenario where. To solve this, we propose a novel algorithm that enables direct reward backpropagation through entire trajectories, by making the non.

Figure 2 from Directly Diffusion Models on Differentiable
For instance, in the inverse folding task, we may prefer protein sequences with high stability. To address this, we consider the scenario where. To solve this, we propose a novel algorithm that enables direct reward backpropagation through entire trajectories, by making the non.

Figure 1 from Directly Diffusion Models on Differentiable
To address this, we consider the scenario where. To solve this, we propose a novel algorithm that enables direct reward backpropagation through entire trajectories, by making the non. For instance, in the inverse folding task, we may prefer protein sequences with high stability.
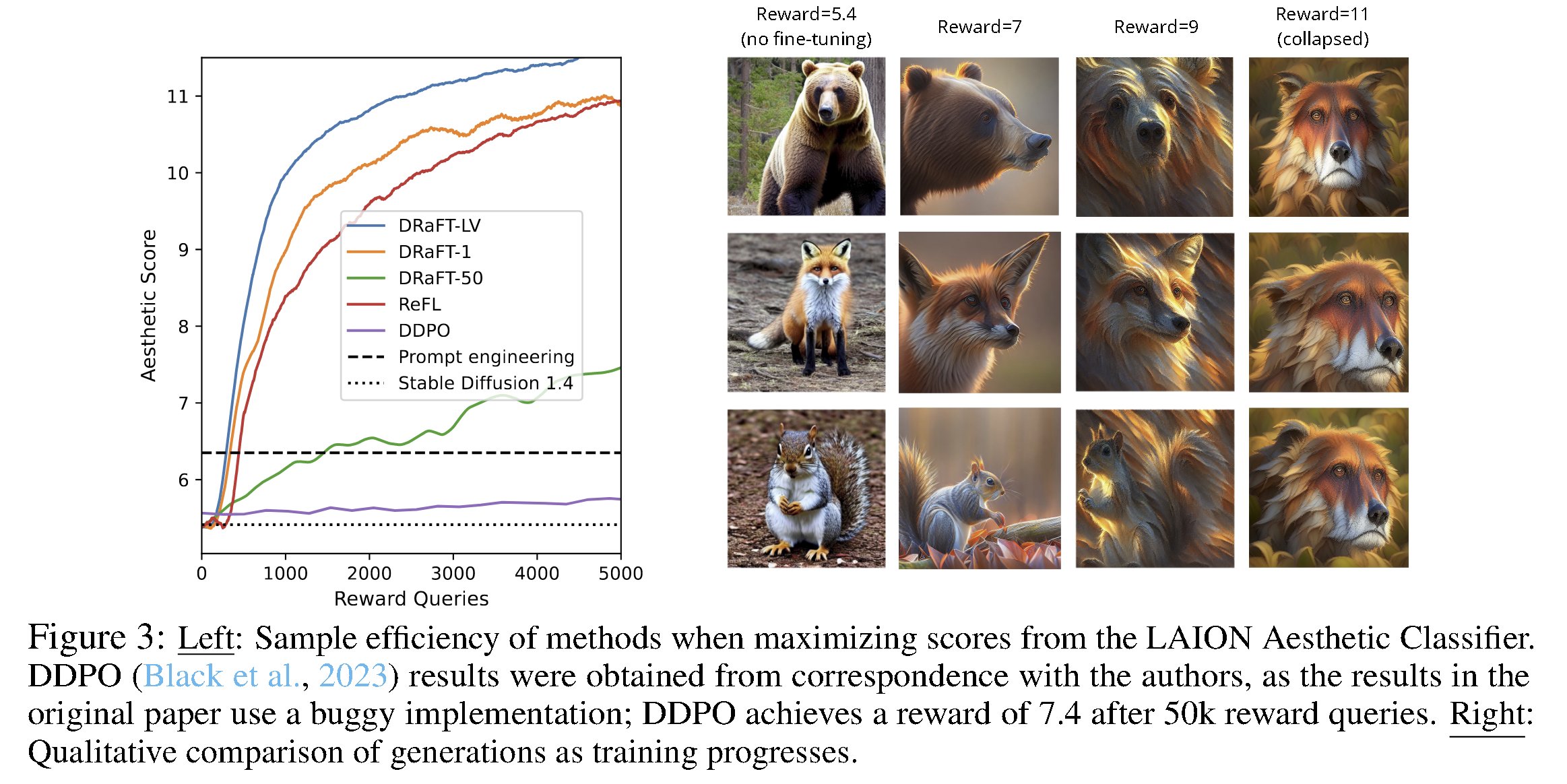
Google DeepMind Introduces Direct Reward (DRaFT) An
For instance, in the inverse folding task, we may prefer protein sequences with high stability. To address this, we consider the scenario where. To solve this, we propose a novel algorithm that enables direct reward backpropagation through entire trajectories, by making the non.

Figure 1 from Directly Diffusion Models on Differentiable
For instance, in the inverse folding task, we may prefer protein sequences with high stability. To solve this, we propose a novel algorithm that enables direct reward backpropagation through entire trajectories, by making the non. To address this, we consider the scenario where.

Boosting TexttoImage Diffusion Models with FineGrained Semantic
For instance, in the inverse folding task, we may prefer protein sequences with high stability. To address this, we consider the scenario where. To solve this, we propose a novel algorithm that enables direct reward backpropagation through entire trajectories, by making the non.

Figure 1 from Directly Diffusion Models on Differentiable
For instance, in the inverse folding task, we may prefer protein sequences with high stability. To solve this, we propose a novel algorithm that enables direct reward backpropagation through entire trajectories, by making the non. To address this, we consider the scenario where.

Figure 1 from Directly Diffusion Models on Differentiable
For instance, in the inverse folding task, we may prefer protein sequences with high stability. To address this, we consider the scenario where. To solve this, we propose a novel algorithm that enables direct reward backpropagation through entire trajectories, by making the non.

SelfPlay of Diffusion Models for TexttoImage Generation
For instance, in the inverse folding task, we may prefer protein sequences with high stability. To address this, we consider the scenario where. To solve this, we propose a novel algorithm that enables direct reward backpropagation through entire trajectories, by making the non.

Table 1 from Directly Diffusion Models on Differentiable
To address this, we consider the scenario where. To solve this, we propose a novel algorithm that enables direct reward backpropagation through entire trajectories, by making the non. For instance, in the inverse folding task, we may prefer protein sequences with high stability.
![[PDF] Directly Diffusion Models on Differentiable Rewards](https://d3i71xaburhd42.cloudfront.net/a395f1c0910a5622f6faaefb5b27e87bb1617759/19-Figure19-1.png)
[PDF] Directly Diffusion Models on Differentiable Rewards
To address this, we consider the scenario where. To solve this, we propose a novel algorithm that enables direct reward backpropagation through entire trajectories, by making the non. For instance, in the inverse folding task, we may prefer protein sequences with high stability.
To Address This, We Consider The Scenario Where.
For instance, in the inverse folding task, we may prefer protein sequences with high stability. To solve this, we propose a novel algorithm that enables direct reward backpropagation through entire trajectories, by making the non.