Does Differentiable Simulator Always Policy Gradient - While differentiable simulators present certain advantages over rl, they are not without their limitations and challenges, such. We know the zobg is always unbiased. How should we choose alpha? Assistant professor, machine learning department @cmu. Consider an interpolated gradient of the two objectives. One of the primary queries arising in this domain is whether differentiable simulators always yield a policy gradient.
One of the primary queries arising in this domain is whether differentiable simulators always yield a policy gradient. While differentiable simulators present certain advantages over rl, they are not without their limitations and challenges, such. We know the zobg is always unbiased. Assistant professor, machine learning department @cmu. Consider an interpolated gradient of the two objectives. How should we choose alpha?
How should we choose alpha? While differentiable simulators present certain advantages over rl, they are not without their limitations and challenges, such. Consider an interpolated gradient of the two objectives. We know the zobg is always unbiased. One of the primary queries arising in this domain is whether differentiable simulators always yield a policy gradient. Assistant professor, machine learning department @cmu.

Accelerated Policy Learning with Parallel Differentiable Simulation
How should we choose alpha? We know the zobg is always unbiased. Consider an interpolated gradient of the two objectives. One of the primary queries arising in this domain is whether differentiable simulators always yield a policy gradient. While differentiable simulators present certain advantages over rl, they are not without their limitations and challenges, such.
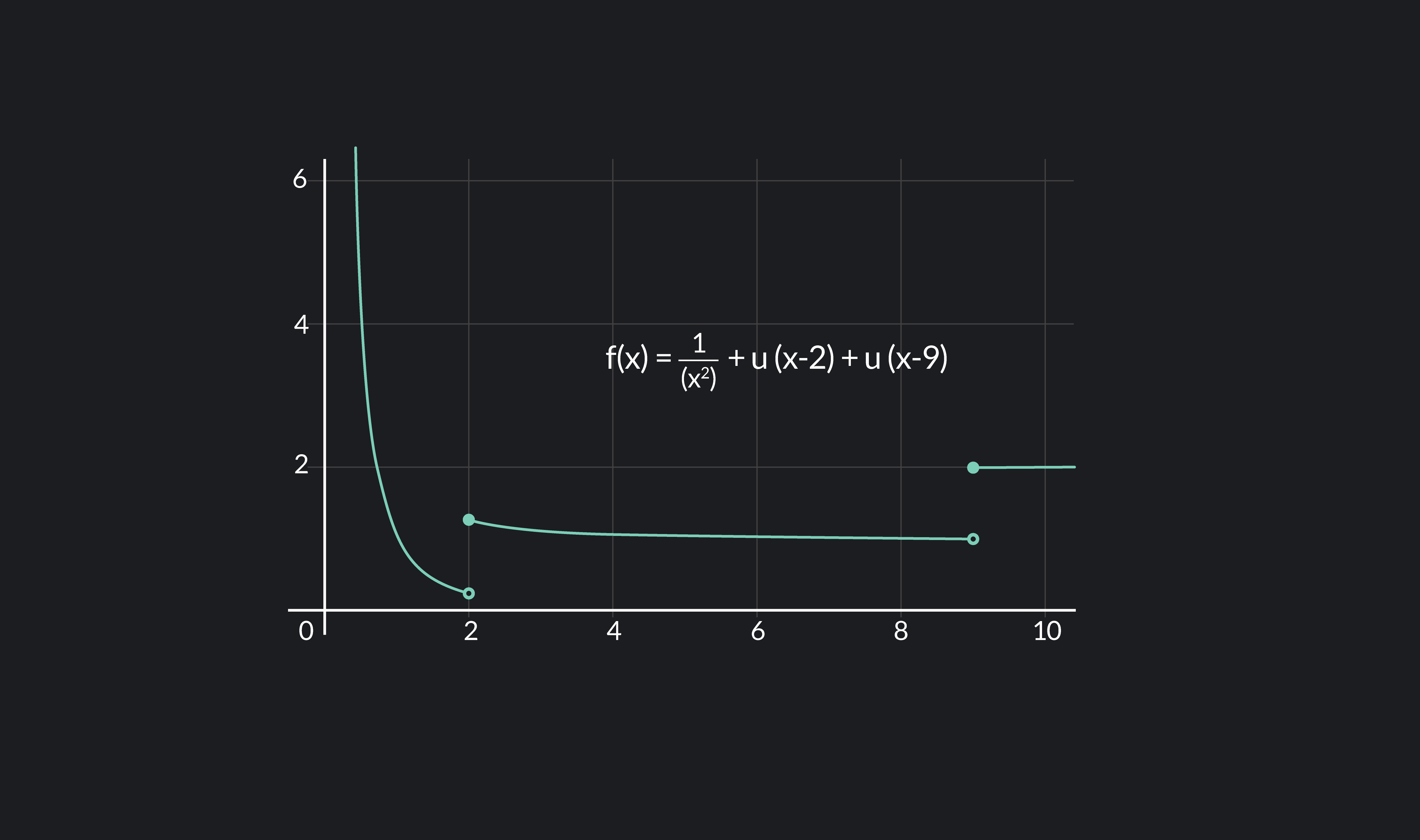
Differentiable Function Meaning, Formulas and Examples Outlier
We know the zobg is always unbiased. Assistant professor, machine learning department @cmu. Consider an interpolated gradient of the two objectives. How should we choose alpha? One of the primary queries arising in this domain is whether differentiable simulators always yield a policy gradient.
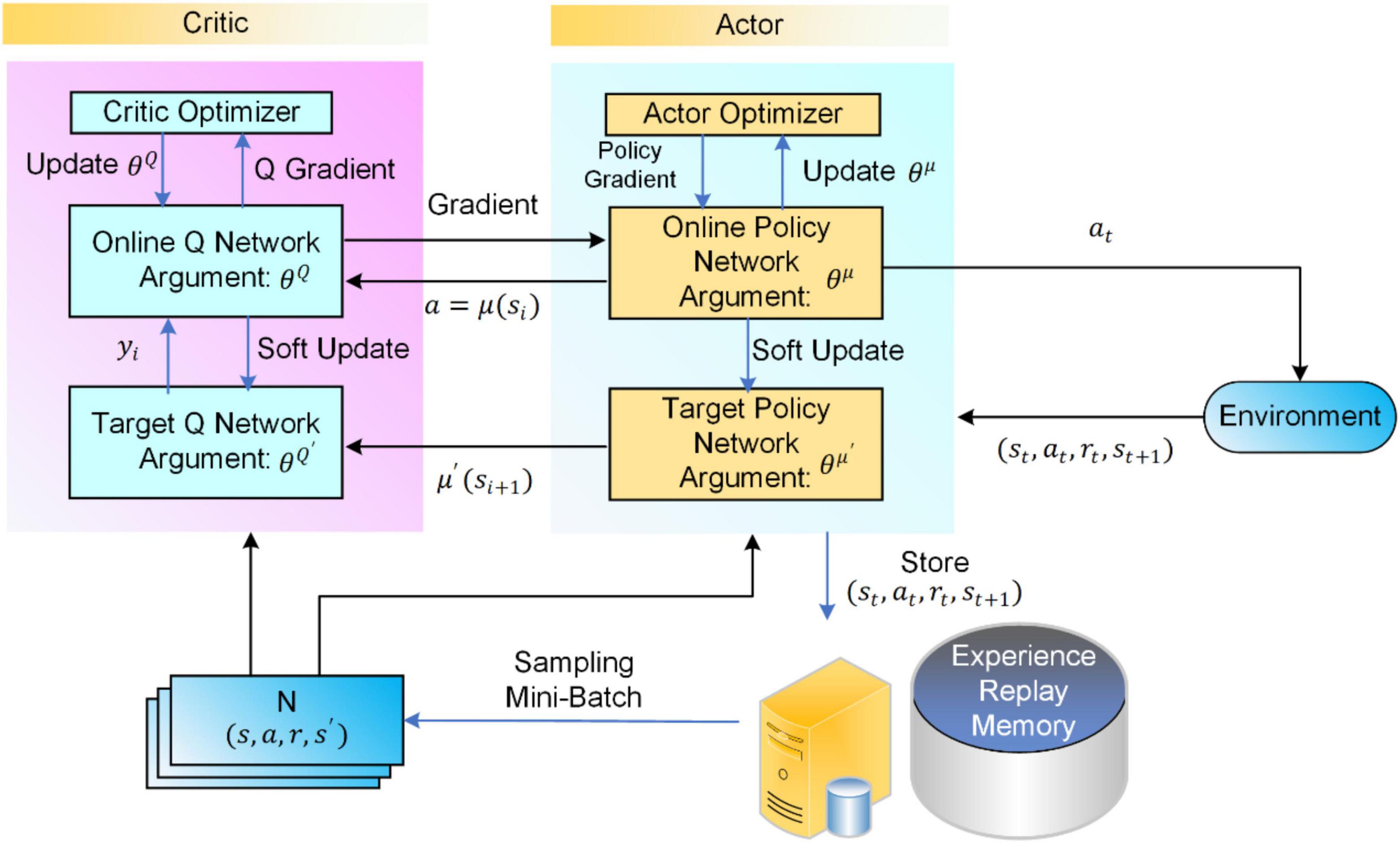
Deep Deterministic Policy Gradient Algorithm Quant RL
How should we choose alpha? We know the zobg is always unbiased. Consider an interpolated gradient of the two objectives. While differentiable simulators present certain advantages over rl, they are not without their limitations and challenges, such. Assistant professor, machine learning department @cmu.

reinforcement learning Policy gradient theorem proofs Cross Validated
While differentiable simulators present certain advantages over rl, they are not without their limitations and challenges, such. How should we choose alpha? Assistant professor, machine learning department @cmu. We know the zobg is always unbiased. Consider an interpolated gradient of the two objectives.

Deep deterministic policy gradient algorithm Download Scientific Diagram
Assistant professor, machine learning department @cmu. One of the primary queries arising in this domain is whether differentiable simulators always yield a policy gradient. While differentiable simulators present certain advantages over rl, they are not without their limitations and challenges, such. We know the zobg is always unbiased. How should we choose alpha?
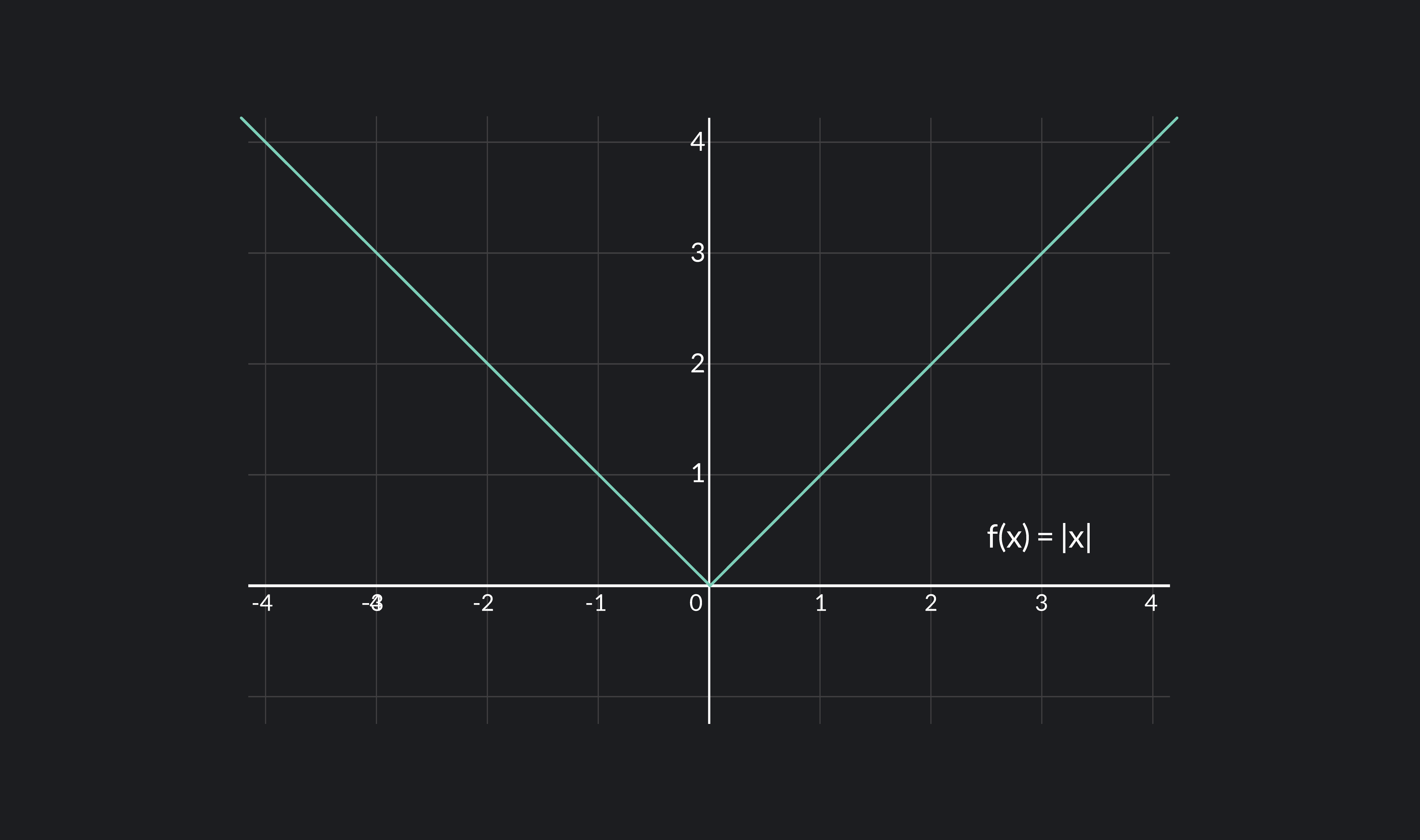
Differentiable Function Meaning, Formulas and Examples Outlier
How should we choose alpha? Consider an interpolated gradient of the two objectives. One of the primary queries arising in this domain is whether differentiable simulators always yield a policy gradient. While differentiable simulators present certain advantages over rl, they are not without their limitations and challenges, such. We know the zobg is always unbiased.

Policy gradient estimation. Download Scientific Diagram
We know the zobg is always unbiased. Assistant professor, machine learning department @cmu. While differentiable simulators present certain advantages over rl, they are not without their limitations and challenges, such. How should we choose alpha? One of the primary queries arising in this domain is whether differentiable simulators always yield a policy gradient.

Do Differentiable Simulators Give Better Policy Gradients? DeepAI
While differentiable simulators present certain advantages over rl, they are not without their limitations and challenges, such. We know the zobg is always unbiased. Consider an interpolated gradient of the two objectives. Assistant professor, machine learning department @cmu. How should we choose alpha?

Differentiable Function Meaning, Formulas and Examples Outlier
Assistant professor, machine learning department @cmu. One of the primary queries arising in this domain is whether differentiable simulators always yield a policy gradient. While differentiable simulators present certain advantages over rl, they are not without their limitations and challenges, such. Consider an interpolated gradient of the two objectives. How should we choose alpha?
PolicyGradientMethods/DDPG.ipynb at master · cyoon1729/Policy
How should we choose alpha? One of the primary queries arising in this domain is whether differentiable simulators always yield a policy gradient. Consider an interpolated gradient of the two objectives. We know the zobg is always unbiased. While differentiable simulators present certain advantages over rl, they are not without their limitations and challenges, such.
We Know The Zobg Is Always Unbiased.
One of the primary queries arising in this domain is whether differentiable simulators always yield a policy gradient. Assistant professor, machine learning department @cmu. While differentiable simulators present certain advantages over rl, they are not without their limitations and challenges, such. Consider an interpolated gradient of the two objectives.